Portal Foundation
PORTALOS
Local AI command-line interface with Ollama and llama.cpp support.
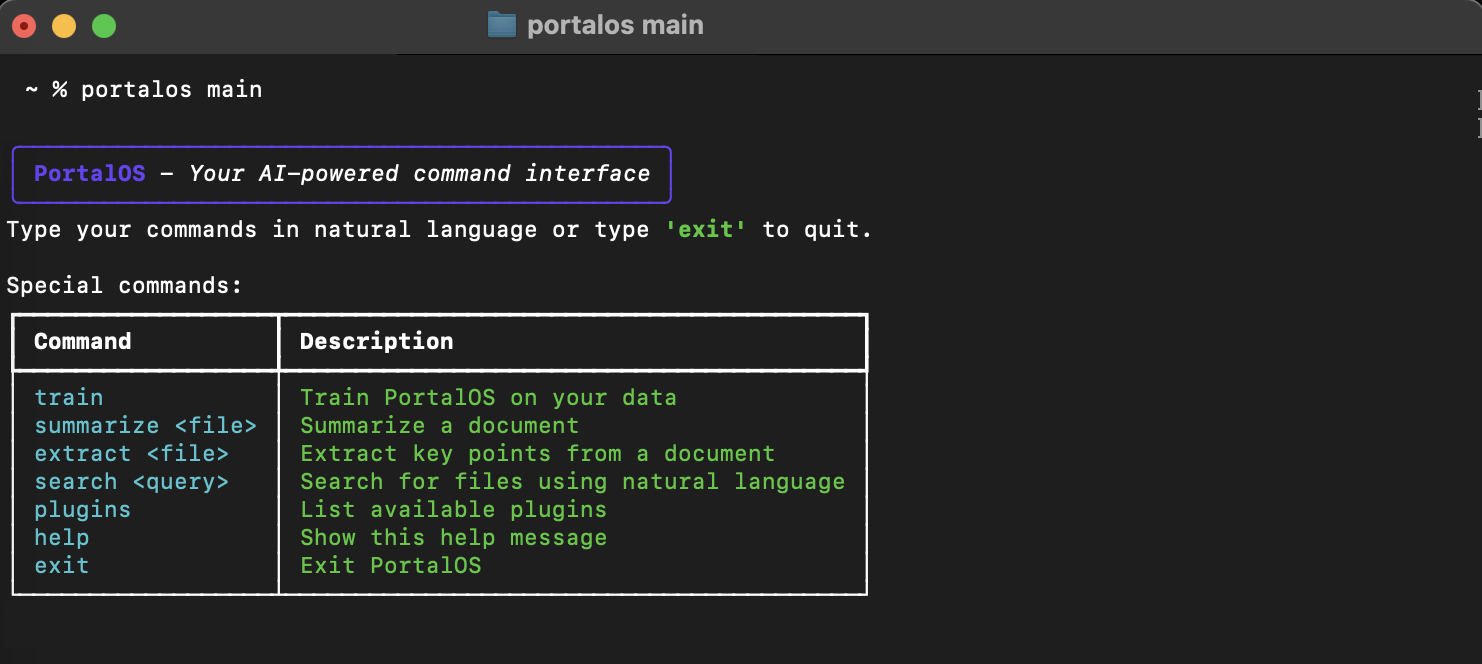
PortalOS
What It Is
Local AI command-line interface. Runs LLMs (LLaMA, Mistral, Phi) via Ollama or llama.cpp on your machine. No cloud dependencies. Natural language commands for file operations, document processing, and system control.
The Problem
Cloud-based AI tools:
- Send data to external servers
- Require internet connection
- Limited control over model behavior
Local alternatives are often fragmented or require significant setup.
The Solution
Single CLI that:
- Runs entirely locally
- Supports multiple model backends
- Processes documents and files via natural language
- Executes system commands
How It Works
- Select model backend (Ollama or llama.cpp)
- Launch PortalOS in terminal
- Issue natural language commands
- Processing happens locally
- Output returned in terminal
Capabilities
Document Processing
- PDF, Markdown, TXT parsing
- OCR via Tesseract
- Summarization
- Key point extraction
File Operations
- Natural language file search
- Semantic search across content
- Batch operations
- Folder organization
System Control
- Execute shell commands via text
- Monitor CPU, RAM, disk
- Task automation
- Background process management
Model Backends
| Backend | Use Case |
|---|---|
| Ollama | Modern systems, 8GB+ RAM, easy model switching |
| llama.cpp | Resource-constrained devices, quantized models |
| Custom | Fine-tuned or domain-specific models |
Supported models: LLaMA, Mistral, Phi, and others.
Technical Architecture
- Modular NLP pipeline
- Context memory management
- Plugin support
- Cross-platform (Linux, macOS, Windows)
- RAG for personal knowledge bases
Development Status
| Milestone | Target | Status |
|---|---|---|
| Core CLI and file operations | Q2 2025 | Live |
| Ollama and llama.cpp integration | Q2 2025 | Live |
| Advanced document parsing, OCR | Q3 2025 | In Progress |
| Plugin system | Q3 2025 | In Progress |
| Personal RAG training | Q4 2025 | Planned |
| Multimodal support | Q1 2026 | Planned |